Cómo la ‘inferencia’ está impulsando la competencia por el dominio de los chips de inteligencia artificial de Nvidia
Los rivales centran sus esfuerzos en cómo se implementa la IA, en sus esfuerzos por perturbar a la empresa de semiconductores más valiosa del mundo.
Los rivales de Nvidia están aprovechando una nueva oportunidad para romper su dominio en el sector de chips de inteligencia artificial después de que la start-up china DeepSeek acelerara un cambio en los requisitos informáticos de la IA.
El R1 de DeepSeek y otros modelos denominados de “razonamiento”, como el o3 de OpenAI y el Claude 3.7 de Anthropic, consumen más recursos informáticos que los sistemas de IA anteriores en el momento en que un usuario realiza su solicitud, un proceso denominado “inferencia”.
Esto ha cambiado el enfoque de la demanda de computación de IA, que hasta hace poco se centraba en el entrenamiento o la creación de un modelo. Se espera que la inferencia se convierta en una parte cada vez mayor de las necesidades de la tecnología a medida que aumenta la demanda entre los individuos y las empresas de aplicaciones que van más allá de los populares chatbots actuales, como ChatGPT o Grok de xAI.
Es aquí donde los competidores de Nvidia (que van desde empresas emergentes fabricantes de chips de inteligencia artificial como Cerebras y Groq hasta procesadores aceleradores personalizados de grandes empresas tecnológicas como Google, Amazon, Microsoft y Meta) están centrando sus esfuerzos para revolucionar a la empresa de semiconductores más valiosa del mundo.
“El entrenamiento crea la IA y la inferencia utiliza la IA”, dijo Andrew Feldman, director ejecutivo de Cerebras. “Y el uso de la IA se ha disparado… La oportunidad actual de fabricar un chip que sea mucho mejor para la inferencia que para el entrenamiento es mayor que nunca”.
Nvidia domina el mercado de los grandes clústeres informáticos, como la instalación xAI de Elon Musk en Memphis o el proyecto Stargate de OpenAI con SoftBank, pero sus inversores buscan garantías de que puede seguir superando a sus rivales en centros de datos mucho más pequeños en construcción que se centrarán en la inferencia.
Vipul Ved Prakash, director ejecutivo y cofundador de Together AI, un proveedor de servicios en la nube centrado en la inteligencia artificial que fue valorado en 3.300 millones de dólares el mes pasado en una ronda liderada por General Catalyst, dijo que la inferencia era un «gran objetivo» para su negocio. «Creo que ejecutar inferencias a escala será la mayor carga de trabajo en Internet en algún momento», dijo.
Los analistas de Morgan Stanley han estimado que más del 75 por ciento de la demanda energética y computacional de los centros de datos en Estados Unidos será para inferencia en los próximos años, aunque advirtieron de una “incertidumbre significativa” sobre cómo se desarrollará exactamente la transición.
Aun así, eso significa que cientos de miles de millones de dólares en inversiones podrían fluir hacia instalaciones de inferencia en los próximos años, si el uso de IA continúa creciendo al ritmo actual.
Los analistas de Barclays estiman que el gasto de capital para inferencia en “IA de frontera” (en referencia a los sistemas más grandes y avanzados) superará al de entrenamiento en los próximos dos años, pasando de 122.600 millones de dólares en 2025 a 208.200 millones de dólares en 2026.
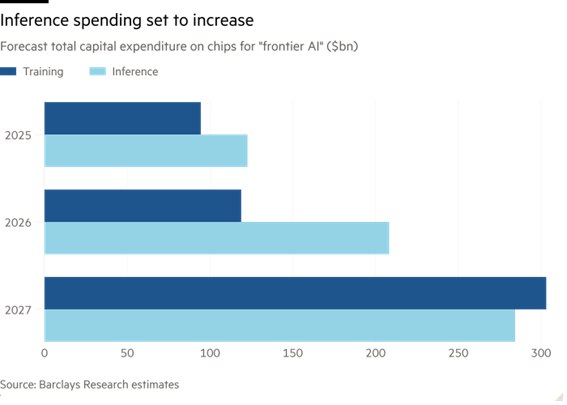
Aunque Barclays predice que Nvidia tendrá «prácticamente el 100 por ciento de la cuota de mercado» en el entrenamiento de inteligencia artificial de vanguardia, «a largo plazo» sólo cubrirá el 50 por ciento de la computación de inferencia. Eso deja a los rivales de la empresa con casi 200.000 millones de dólares en gastos de chips por los que jugarse de aquí a 2028.
“Hay una enorme demanda de chips mejores, más rápidos y más eficientes”, afirmó Walter Goodwin, fundador de la empresa emergente de chips Fractile, con sede en el Reino Unido. Los proveedores de computación en la nube están ansiosos por tener “algo que elimine la dependencia excesiva” de Nvidia, agregó.
El director ejecutivo de Nvidia, Jensen Huang, insistió en que los chips de su compañía son tan potentes para la inferencia como para el entrenamiento, mientras vislumbra una nueva y gigantesca oportunidad de mercado.
Los últimos chips Blackwell de la empresa estadounidense fueron diseñados para manejar mejor la inferencia y muchos de los primeros clientes de esos productos los están utilizando para proporcionar servicios a los sistemas de IA, en lugar de entrenarlos. La popularidad de su software, basado en su arquitectura patentada Cuda, entre los desarrolladores de IA también representa una barrera formidable para los competidores.
“La cantidad de cálculo de inferencia necesaria ya es 100 veces mayor” que cuando comenzaron los modelos de lenguaje de gran tamaño, dijo Huang en la conferencia telefónica sobre ganancias del mes pasado. “Y eso es solo el comienzo”.
El costo de entregar respuestas de LLM ha disminuido rápidamente en los últimos dos años, impulsado por una combinación de chips más potentes, sistemas de IA más eficientes y una intensa competencia entre desarrolladores de IA como Google, OpenAI y Anthropic.
“El costo de usar un determinado nivel de IA se reduce aproximadamente 10 veces cada 12 meses, y los precios más bajos conducen a un uso mucho mayor”, dijo Sam Altman, director ejecutivo de OpenAI, en una publicación de blog el mes pasado.
Los modelos v3 y R1 de DeepSeek, que provocaron pánico en el mercado de valores en enero en gran parte debido a lo que se percibía como menores costos de capacitación , han ayudado a reducir aún más los costos de inferencia, gracias a las innovaciones arquitectónicas y las eficiencias de codificación de la empresa emergente china.
Al mismo tiempo, el tipo de procesamiento requerido por las tareas de inferencia (que pueden incluir requisitos de memoria mucho mayores para responder consultas más largas y complejas) abrió la puerta a alternativas a las unidades de procesamiento gráfico de Nvidia, cuyas fortalezas residen en el manejo de volúmenes muy grandes de cálculos similares.
«El rendimiento de la inferencia en su hardware es una función de qué tan rápido puede [mover datos] hacia y desde la memoria», dijo Feldman de Cerebras, cuyos chips han sido utilizados por la empresa emergente francesa de inteligencia artificial Mistral para acelerar el rendimiento de su chatbot, Le Chat.
La velocidad es vital para atraer a los usuarios, afirmó Feldman. “Una de las cosas que demostró Google [la búsqueda] hace 25 años es que incluso microsegundos [de retraso] reducen la atención del espectador”, afirmó. “Estamos produciendo respuestas para Le Chat en un segundo, mientras que el o1 [de OpenAI] habría tardado 40”.
Nvidia sostiene que sus chips son tan potentes para la inferencia como para el entrenamiento, y señala que su rendimiento de inferencia se ha multiplicado por 200 en los últimos dos años. Afirma que hoy en día cientos de millones de usuarios acceden a productos de IA a través de millones de sus GPU.
“Nuestra arquitectura es fungible y fácil de usar en todas esas formas diferentes”, dijo Huang el mes pasado, tanto para construir modelos grandes como para ofrecer aplicaciones de IA de nuevas maneras.
Prakash, cuya empresa cuenta con Nvidia como inversor, dijo que Together utiliza hoy en día los mismos chips Nvidia para inferencia y entrenamiento, lo cual es “bastante útil”.
A diferencia de las GPU de «propósito general» de Nvidia, los aceleradores de inferencia funcionan mejor cuando están ajustados a un tipo particular de modelo de IA. En una industria que evoluciona rápidamente, eso podría resultar un problema para las empresas emergentes de chips que apuesten por la arquitectura de IA incorrecta.
“Creo que una de las ventajas de la computación de propósito general es que, a medida que las arquitecturas de los modelos cambian, se tiene más flexibilidad”, dijo Prakash, y agregó: “Tengo la sensación de que habrá una combinación compleja de silicio en los próximos años”. Información adicional de Michael Acton en San Francisco.
