Quispe Chequea: una plataforma de verificación con inteligencia artificial en lenguas originarias
La primera vez que el traductor Ebert Villanueva escuchó su propia voz diciendo algo que él nunca había pronunciado antes, quedó tan sorprendido como quien ve un espejismo. Se trataba de un audio en quechua que advertía de alguna versión falsa propalada en redes sociales. El mensaje explicaba por qué la versión era falsa y cuál era el dato real que los oyentes debían conocer. Villanueva, un experimentado intérprete de quechua chanka acreditado ante el Ministerio de Cultura, reconoció de inmediato que era su manera de hablar, su timbre y entonación, pero ese audio no había salido de su boca. Le tomaría un instante asumir que era un mensaje generado con inteligencia artificial, una versión clonada de su voz en una herramienta digital desarrollada por este medio como un recurso para combatir la desinformación: Quispe Chequea.
Ebert Villanueva es uno de los tres traductores e intérpretes que a lo largo de un año participaron en un equipo multidisciplinario para construir una herramienta destinada a llevar mensajes confiables a las comunidades de la región andina y amazónica. Quiere decir que, a lo largo del proceso, tuvo la tarea de realizar traducciones de textos al quechua y luego pasó días en un estudio de grabación para registrarlas, con la ayuda de un ingeniero de sonido, con el fin de generar un banco de datos en audio que serviría para el proceso de replicar su voz con la pronunciación original de su lengua.
El resultado es una plataforma digital que genera textos y permite traducirlos y además convertirlos en seguida en mensajes de audio en los idiomas quechua como aimara y awajún, en lo que apunta a ser una experiencia transformadora para el periodismo de distintas regiones del país: la posibilidad de producir contenido riguroso, de manera automatizada y en lenguas originarias, para difundirlo por radios de nueve regiones del país.
El nombre de la herramienta no es gratuito: un millón de personas en el Perú llevan el apellido Quispe, cuyo significado alude a la claridad y la transparencia. El prototipo desarrollado por OjoPúblico, con el apoyo de la Google News Initiative, sigue ambos sentidos mediante un experimento tecnológico que se enmarca en la actual carrera global del periodismo para diseñar los mejores usos para la inteligencia artificial frente al fenómeno de la desinformación.
EL NOMBRE DE LA HERRAMIENTA NO ES GRATUITO: EL SIGNIFICADO DEL APELLIDO QUISPE ALUDE A LA CLARIDAD Y LA TRANSPARENCIA.
¿Qué hace Quispe Chequea?
Quispe Chequea es una plataforma periodística diseñada bajo parámetros de verificación, una metodología de estándar internacional que establece el uso de evidencia fáctica, identificable y abierta como requisito para determinar la veracidad o falsedad de una versión de interés público. Consiste en un gestor de contenido que contempla campos para los datos de la versión detectada, las fuentes que permiten revisar el tema, y los eventuales comentarios o descargos del involucrado.
Con base en esta información, la plataforma aplica dos tipos de recursos de inteligencia artificial: el primero es la funcionalidad de los llamados modelos de lenguaje masivo (LLM por sus siglas en inglés), unos sistemas computacionales capaces de analizar grandes volúmenes de datos, encontrar patrones y ofrecer respuestas similares a las del lenguaje humano. En este caso, el prototipo de OjoPúblico se basa en el modelo usado por ChatGPT para la conversión de la data en un chequeo periodístico, con un alto grado de precisión ortográfica, correcta sintaxis y claridad expositiva.
El otro recurso es un modelo de síntesis de voz, que, en términos simples, permite convertir textos en una representación visual de frecuencias de audio, a manera de un espectrograma, y luego reproducir esos gráficos en el formato de audio correspondiente. En este caso, esta tecnología permite convertir los textos traducidos durante la primera etapa en audios en los idiomas quechua, aimara y awajún, como lo haría un locutor que lee en voz alta una noticia o un creador de contenidos en podcast.
“Este proyecto es importante porque apunta a garantizar los derechos lingüísticos de la ciudadanía a través del acceso a noticias y contenido de su entorno en lenguas originarias”, comenta Ebert Villanueva, el primero de los traductores que escuchó su voz replicada mediante esta herramienta.
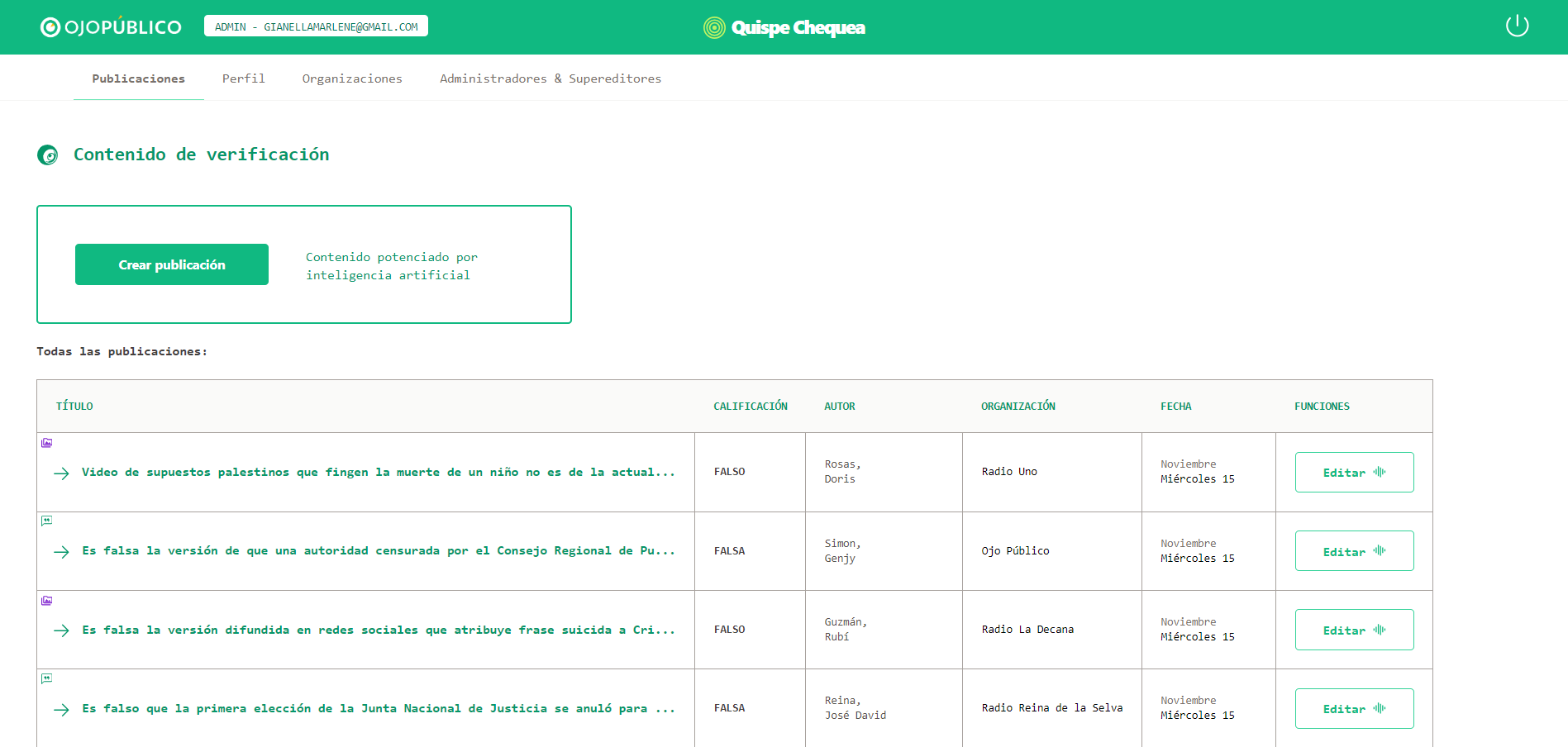
La plataforma tiene una interfaz amigable, con distintos campos para colocar textos, editar los resultados, visualizar las fuentes y descargar los audios. De este modo, facilita la tarea informativa de comunicadores de 12 radioemisoras aliadas de OjoPúblico, quienes forman parte de esta alianza contra la desinformación en las regiones Loreto, Junín, Amazonas, Piura, San Martín, Ayacucho, Apurímac, Puno y Tacna.
“La inteligencia artificial ingresa para poder apoyar la relevancia de otros idiomas, es muy importante y fundamental. No solamente para mí, sino para las generaciones que vienen”, dice Nora Oliva Quispe, integrante de la Red de Comunicadores Indígenas del Perú (Redcip), quien pudo conocer la herramienta durante una presentación especial de Quispe Chequea a un grupo de comunicadores de organizaciones indígenas de los Andes y la Amazonía.
Cómo crear voces con IA
A la experiencia de Ebert Villanueva se sumó la de dos intérpretes en lenguas originarias: Ecker Ramos, en aimara, y Yanua Atamain, en awajún (iinia chicham). Ambos son miembros de comunidades de Puno y San Martín, respectivamente, y en los últimos tres años han desempeñado una labor crucial en la traducción de verificaciones producidas por OjoBiónico para pueblos originarios. Los contenidos, que aclaraban desde engaños sobre la pandemia hasta asuntos de la crisis política, fueron emitidos por radios regionales, y en cierta zona de difícil acceso incluso se difundieron por medio de un altoparlante colocado en el centro de una plaza comunal, como en el caso de la comunidad de Río Soritor, en la región amazónica de San Martín. El salto que este nuevo proyecto representa un uso innovador de la tecnología para afrontar contextos difíciles.
“Hemos creado cosas desde cero”, explica el desarrollador Jorge Miranda, quien lideró el equipo técnico encargado implementar la plataforma, en referencia a que uno de los mayores desafíos: la limitada disponibilidad de contenido digital en lenguas originarias.
En una primera etapa de documentación, el equipo detectó distintos servicios que ofrecen la tecnología denominada text-to-speech (texto a voz) mediante recursos de inteligencia artificial. Sin embargo, estas opciones estaban basadas en lo que se conoce como ‘idiomas de altos recursos’, es decir, en lenguas con mucha presencia en el mundo digital –a través de páginas webs, libros electrónicos, emails o redes sociales–, lo que facilita su uso frecuente en modelos de aprendizaje automatizado (machine learning, por su denominación en inglés). Eso significaba que todos los resultados estarían afectados por las características de los idiomas disponibles. Se requería una forma de ‘entrenar’ un modelo propio.
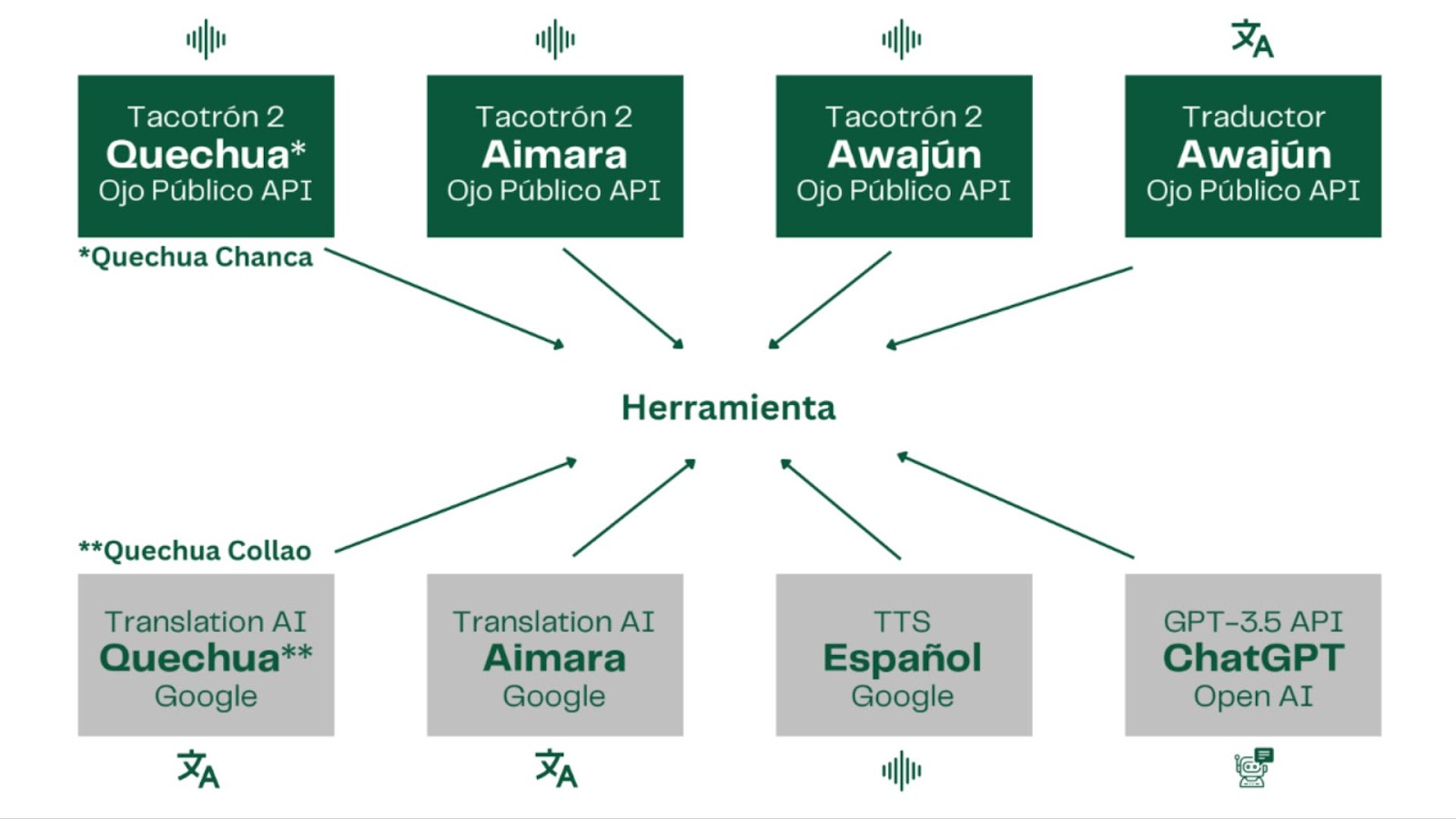
La búsqueda comprendió desde el testeo de herramientas disponibles hasta la revisión de paper académicos sobre el tema. Cuando las opciones parecían reducirse, el equipo de desarrolladores encontró una pista que encaminó el proceso: era un paper elaborado por un equipo de investigadores de la India, especialistas en ingeniería eléctrica y ciencias de la información, que mostraba resultados auspiciosos de una experiencia con el sánscrito, una antigua lengua muy extendida en la región asiática. Los investigadores indios habían utilizado Tacotron 2, un sistema de síntesis de voz, desarrollado por investigadores de Google, que logra reproducir la voz humana a partir de textos, mediante técnicas de aprendizaje profundo.
A partir de entonces, el proceso se encaminó a construir un producto a la medida. El primer paso era reunir la data necesaria.
El equipo de intérpretes trabajó en conjunto con los verificadores de OjoBiónico para crear tres bases de datos. Cada base consistía en una lista de términos y frases usuales en el lenguaje de los textos periodísticos de verificación, que sirvieron de referencia para generar un vocabulario comprensible en las distintas traducciones. Villanueva, Ramos y Atamain trabajaron conjuntos de 5.600 líneas cada uno. Posteriormente, los términos y frases traducidos fueron grabados línea por línea, durante extensas jornadas en estudio. Las sesiones fueron un desafío a la resistencia: había que grabar de manera sostenida, con inevitables repeticiones, ajustes y revisiones. Todo un esfuerzo para obtener bancos sonoros con apenas 3 a 4 horas aproximadamente por idioma.
Una vez reunidos estos conjuntos de datos, se pasó a una etapa de entrenamiento del modelo. En esta fase, los desarrolladores usaron la arquitectura de Tacotron 2 para los procesos de aprendizaje que permitirían a la herramienta convertir textos traducidos en audios. Básicamente, se trata de hacer correr el modelo y esperar los resultados. El proceso tarda algunas horas. Cuando termina, se realizaron pruebas para establecer el grado de precisión del audio, la pronunciación y el grado de naturalidad alcanzado. Los primeros resultados eran poco claros, casi inaudibles. Tras sucesivos entrenamientos, con los respectivos ajustes de parámetros, permitieron alcanzar versiones como la que en su momento sorprendería al traductor Ebert Villanueva como si fuera un espejismo.
Para el entrenamiento de esta estructura usó una base de más de veinte mil frases en awajún.
De momento, la herramienta genera audios en quechua y aimara. La versión en awajún ha requerido un esfuerzo adicional: a diferencia de los primeros, que utilizan recursos del traductor de Google para generar los textos base del proceso, esta lengua amazónica –hablada por poco más de cincuenta mil personas– no dispone de una herramienta de traducción digital. Lo que existen son algunos diccionarios, de alcance limitado. El reto del equipo fue desarrollar una primera experiencia de este tipo.
El encargado de implementarlo fue el científico de datos Óscar Moreno, quien llevaba un tiempo participando de iniciativas para generar modelos de traducción a idiomas nativos. Tras una etapa inicial de investigación, Moreno optó por utilizar la estructura de un modelo de traducción automática del finlandés, que comparte con el awajún la característica de ser idiomas aglutinantes, es decir que sus palabras están formadas por la unión de pequeñas unidades con significado propio.
Para el entrenamiento de esta estructura usó una base de más de veinte mil frases en awajún, con data que procedía tanto de las verificaciones de OjoPúblico como de la Biblia, cuentos y poemas, leyes y normas del Estado.
En una primera prueba con quinientas oraciones, se obtuvo que el 33% de la muestra ofrecía buena calidad de traducción. Este resultado, validado por un intérprete originario awajún, representa un primer avance en el desarrollo de modelos de traducción automáticas del español a lenguas de la Amazonía.
Solo para usuarios entrenados
Por estos días, comunicadores de doce radios, procedentes de nueve regiones, reciben entrenamiento en el uso de Quispe Chequea. En una primera etapa, la capacitación se centra en los criterios de verificación periodística, que exigen el uso de datos fácticos y el descarte de todo elemento subjetivo. Solo quienes superan esta etapa pasan a experimentar con la plataforma, que facilita la generación de formatos para medios de comunicación. Este doble proceso apunta a asegurar el uso responsable de la herramienta, un criterio imperativo en tiempos de los llamados deep fakes, archivos de video, audio o voz fraudulentos generados con recursos de inteligencia artificial.
Los participantes son miembros de medios como Radio Señal Lagunas y Radio la Voz de la Selva, de Loreto; Radio Milenio, de Junín; Radio Reino de la Selva, de Amazonas; Radio Cutivalú, de Piura; Millenium RadioTV, de San Martín; Estación Wari, de Ayacucho; Radio Andahuaylas, de Apurímac; Radio Uno, de Tacna; Radio Pachamama, Radio la Decana y Radio Onda Azul, de Puno.
A la fecha, los participantes han generado 43 verificaciones del discurso público y chequeos a desinformaciones virales.
“La inteligencia artificial ingresa para dar relevancia de nuestros idiomas. Esto es muy importante no solo para mí, sino para las generaciones que vienen”, dice Nora Oliva Quispe, integrante de la Red de Comunicadores Indígenas del Perú (Redcip), quien pudo conocer la herramienta durante una presentación especial de Quispe Chequea a un grupo de comunicadores de organizaciones indígenas de los Andes y la Amazonía.
El futuro de la herramienta es auspicioso. En los próximos meses será parte central de los esfuerzos de OjoPúblico por utilizar formatos múltiples para contrarrestar la desinformación. También para facilitar a comunicadores regionales un nuevo recurso con el cual llevar información confiable a sus audiencias.
